

大数据——MapReduce
日期:2018-09-10 17:59:55 / 人气:2412
MapReduce适合PB级以上海量数据的离线处理MapReduce不擅长什么
实时计算
像MySQL一样,在毫秒级或者秒级内返回结果
流式计算
MapReduce的输入数据集是静态的,不能动态变化
MapReduce自身的设计特点决定了数据源必须是静态的
DAG计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出
MapReduce编程模型
MapReduce将作业job的整个运行过程分为两个阶段:Map阶段和Reduce阶段
Map阶段由一定数量的Map Task组成
输入数据格式解析:InputFormat
输入数据处理:Mapper
数据分组:Partitioner
Reduce阶段由一定数量的Reduce Task组成
数据远程拷贝
数据按照key排序
数据处理:Reducer
数据输出格式:OutputFormat
InputFormat
文件分片(InputSplit)方法
处理跨行问题
将分片数据解析成key/value对
默认实现是TextInputFormat
TextInputFormat
Key是行在文件中的偏移量,value是行内容
若行被截断,则读取下一个block的前几个字符
Split与Block
Block
HDFS中最小的数据存储单位
默认是64MB
Spit
MapReduce中最小的计算单元
默认与Block一一对应
Block与Split
Split与Block是对应关系是任意的,可由用户控制
Combiner
Combiner可做看local reducer
合并相同的key对应的value(wordcount例子)
通常与Reducer逻辑一样
好处
减少Map Task输出数据量(磁盘IO)
减少Reduce-Map网络传输数据量(网络IO)
如何正确使用
结果可叠加
Sum(YES!),Average(NO!)
Partitioner
Partitioner决定了Map Task输出的每条数据交给哪个Reduce Task处理
默认实现:hash(key) mod R
R是Reduce Task数目
允许用户自定义
很多情况需自定义Partitioner
比如“hash(hostname(URL)) mod R”确保相同域名的网页交给同一个Reduce Task处理
Map和Reduce两阶段
Map阶段
InputFormat(默认TextInputFormat)
Mapper
Combiner(local reducer)
Partitioner
Reduce阶段
Reducer
OutputFormat(默认TextOutputFormat)
MapReduce编程模型—内部逻辑
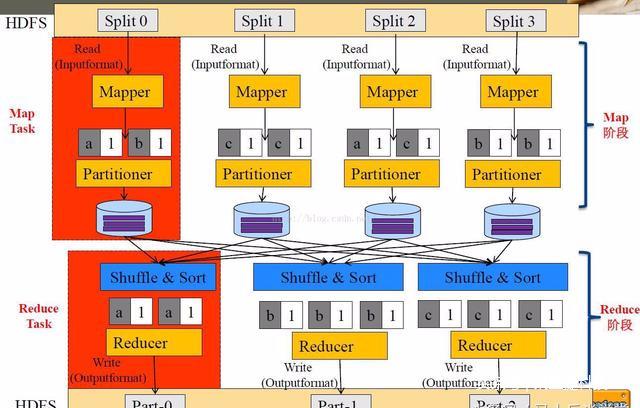
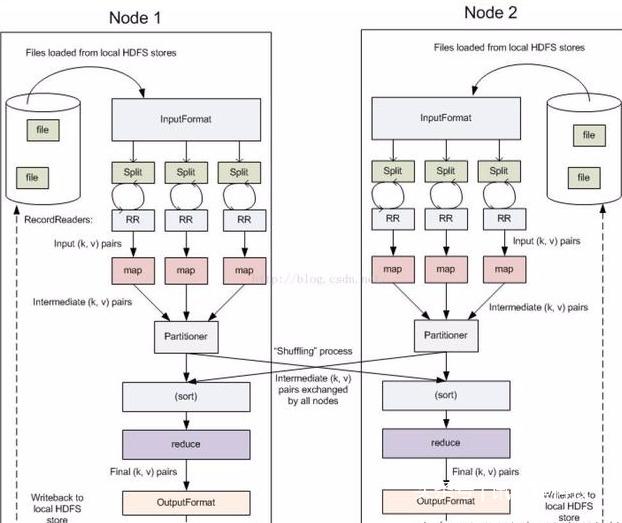
MapReduce编程模型—外部物理结构
MapReduce 2.0架构
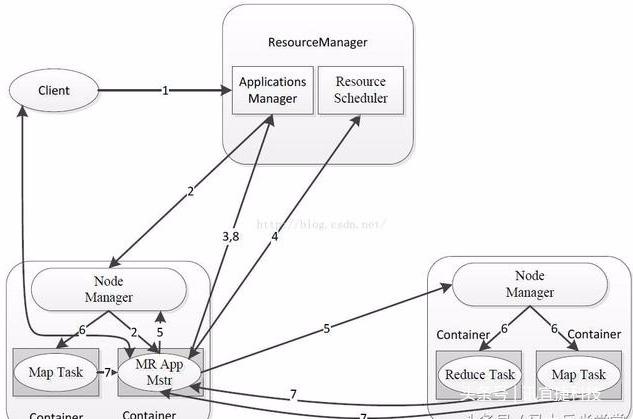
Client
与MapReduce 1.0的Client类似,用户通过Client与YARN交互,提交MapReduce作业,查询作业运行状态,管理作业等。
MRAppMaster
功能类似于 1.0中的JobTracker,但不负责资源管理;
功能包括:任务划分、资源申请并将之二次分配个Map Task和Reduce Task、任务状态监控和容错。
MapReduce 2.0容错性
MRAppMaster容错性
一旦运行失败,由YARN的ResourceManager负责重新启动,最多重启次数可由用户设置,默认是2次。一旦超过最高重启次数,则作业运行失败。
Map Task/Reduce Task
Task周期性向MRAppMaster汇报心跳;
一旦Task挂掉,则MRAppMaster将为之重新申请资源,并运行之。最多重新运行次数可由用户设置,默认4次。
数据本地性
什么是数据本地性(data locality)
如果任务运行在它将处理的数据所在的节点,则称该任务具有“数据本地性”
本地性可避免跨节点或机架数据传输,提高运行效率
数据本地性分类
同节点(node-local)
同机架(rack-local)
其他(off-switch)
推测执行机制
作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map任务和Reduce任务构成
因硬件老化、软件Bug等,某些任务可能运行非常慢
推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度
为拖后腿任务启动一个备份任务,同时运行
谁先运行完,则采用谁的结果
不能启用推测执行机制
任务间存在严重的负载倾斜
特殊任务,比如任务向数据库中写数据
常见MapReduce应用场景
简单的数据统计,比如网站pv、uv统计
搜索引擎建索引 (mapreduce产生的原因)
海量数据查找
复杂数据分析算法实现
聚类算法
分类算法
推荐算法
图算法
作者:admin
新闻资讯 News
- 讯宜捷成功签约深圳芯而达05-18
- 讯宜捷成功签约洛阳锐英机械05-18
- 讯宜捷成功签约深圳美达05-18
- 讯宜捷成功签约河南渡渡鸟网络科...05-18
案例展示 Case
- 地跨“半壁江山”06-23
- 【蒙牛清远】设备维护保养系统再...05-18
- 【青木合众】复杂问题简单化就是...05-10
- 【乐山商场】拯救零售服务的商业...05-05
- 【国企中石油】税银综合管理平台...05-15
- 【上田财富】信息化财富管理机构...05-05